Vert.x concurrency model
written on July 7, 2021Vert.x is one of Java's gems that are less known but excels in performance and resource efficiency. However, first step in using it effectively is to understand its concurrency model. Recent changes in Vert.x 4 tried to simplify this model a bit, but this still could bring surprises specially for developers having backgrounds in other frameworks.
This post tries to give a short yet understandable overview of Vert.x's concurrency model.
Vert.x avoids two things to increase performance: constantly creating and destroying threads and blocking current thread for long tasks. In Vert.x this is described by using the async APIs and implemented by a combination of different solutions.
We will come to the API in another post, but I want to first talk more about the solution as this is important to understand the API later. At first place, Vert.x tries to reduce context switches and overhead of creating and disposing threads as far as possible.
Context switches and changing active threads can cost a lot of processing power.
That's why Vert.x tries to use a set of always active threads and instead defines the concept of verticle.
A verticle is very similar to what an agent is in other reactive systems. A verticle has a single responsibility and runs over and over with different input to process it and generate results based on that input. These results could simply be further tasks that are sent to other verticles to be processed. Verticles communicate using messages with each other to build a larger unit and a complete system.
Vert.x starts a pool of threads and runs instances of verticles using those threads.
It is guaranteed by Vert.x that each verticle instance always runs with the same thread.
Vert.x also guarantees that no single verticle instance will be called concurrently.
Meaning that handle() method of each verticle instance will run from beginning to the end before being called with a new input.
These are very important points as they free developers from a lot of side effects of concurrency.
Accessing static resources still should be done with care as this might mean concurrent access.
Threads that run the normal verticles' code are called event loop threads.
Following picture shows many verticle instances with their dedicated threads (event loops).
Verticles highlighted with border are the ones currently being run on that thread.
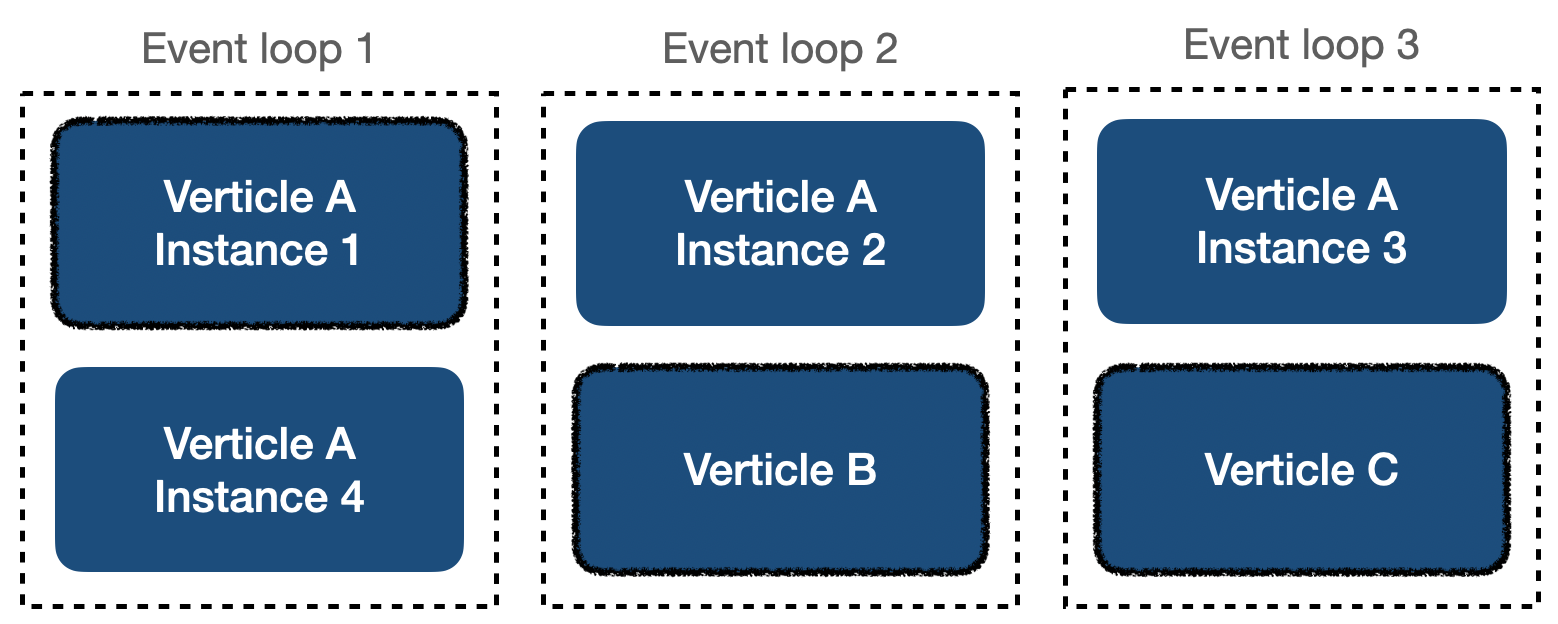
One way to scale in Vert.x is to deploy more instances of one verticle.
Let's say you have 2 types of verticles: A and B. If your system has too much work for type A, you will simply deploy many instances of A and less or just one instance of type B.
Another basic concept of Vert.x is not blocking. This means whatever that takes long should be handed over to a background process and current thread shall not be blocked for its completion, resources shall not be wasted by waiting.
Not blocking is done by different means. Disk or network I/O should be done using the async libraries provided by Vert.x. These dispatch the request and subscribe to receive the response. Current thread is then freed and starts handling next request on next verticle. When the result is available and as soon as the thread responsible for running the verticle becomes free, processing will continue.
In some cases one verticle might need to ask other verticles to do processing for it, then gather responses and generate a final response/result to original request/input. During this whole time the first verticle does not block the thread it was running on, but rather lets it to be used for running other verticles.
Whatever that takes long has to be done async and shall not block.
You might still ask what if your code has no I/O but still takes long to run. It also does not make sense to break it into multiple verticles just to have many small pieces, adding lots of messaging and potentially network overhead. For this case Vert.x has the concept of worker verticles. These are the type of verticles that does their processing on another pool of threads, normally with lower priority. These verticles can take longer to do their job but need to be used with care as excessive use might defeat the purpose. As mentioned before, verticles communicate with each other using messages. This also applies to worker verticles and normal ones. The best way to run a long-running taking task is that normal verticles dispatch work to worker ones and just subscribe to the result, continuing after its received.
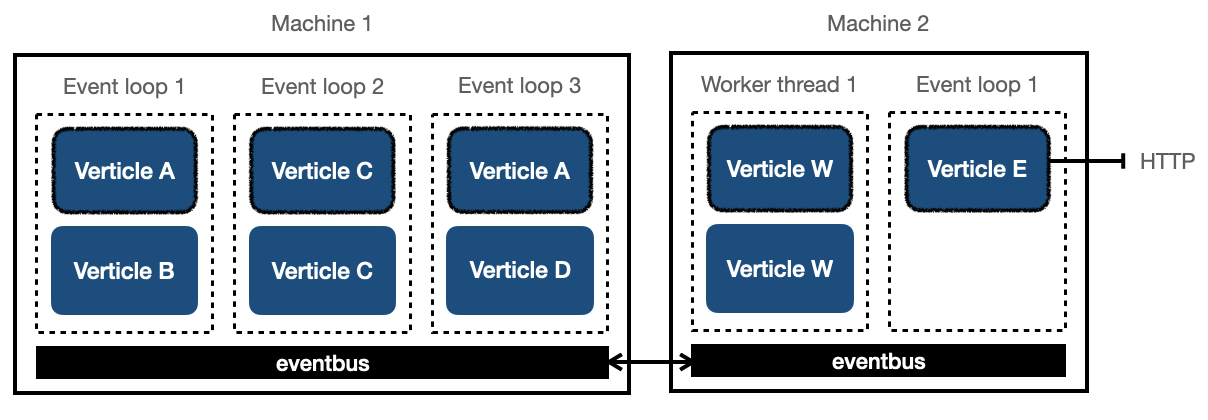
Vert.x calls the communication channel that connects verticles and takes care of delivering messages, eventbus. The important fact is that, it is possible to extend eventbus over multiple JVMs, machines and even to the frontend. This means for example worker verticles might even be deployed on a stronger machine! This is another way to scale in Vert.x and this is how clusters are formed in Vert.x.
Following picture shows a complex setup that Vert.x might be used for distributing tasks
(like handling requests) over many machines:
I hope this gives you a good head start on how threading and concurrency works in Vert.x. In future posts we will revisit and deepen these topics further more.