S3 & CloudFront as complete access controlled file storage
written on July 13, 2015Recently during our project, we needed an access controlled file storage which should have been plugged into our under development system. Problem was that the system we are talking about had already a complicated access control logic and we neither intended to reimplement all that logic in another language nor it fulfilled our intention regarding performance of the file serving system to have any kind of cache, database lookups inside.
After some brainstorming and considerations, we found two possible solutions:
- Extend our system to generate some URLs based on access control logic using cryptographic methods and return it to users for accessing the file servers. On the other side use the great nginx, develop some verification logic using either lua or any other language that nginx has a plugin for it to check validity of URL with out any kind of DB interactions.
- Again generate URLs on our own system but then use S3 and CloudFront instead of nginx for verification and serving data.
We were considering some limitations for file access like:
- date and time period that user may use generated URL
- kind of action that user is allowed to use URL for, create a new resource, update an existing one or delete one
- both upload and download process shall go through this access control system and there should be no other way of accessing files
The first option had clearly the benefit of total flexibility. However the clear advantage of CloudFront is the wide spread delivery and cache network and speed up that it provide plus the fact that we are not going to reinvent the wheel and waste our time on debugging yet another application/script.
The result of all the brainstorming was to try S3-CF combination and see if that works and in worst case to fall back on nginx solution. However choosing S3-CF combination proved to be the right choice even though we where forced to change our requirements a bit.
What does S3 and CloudFront provide?
As you may already know, S3 is the extremely cheap file storage that Amazon provides as part of its cloud services. There is a lot to know about S3, but for more than this you may best refer to AWS documentation itself.
CloudFront is a distribution network that intends to speed up (more static but also dynamic) content serving from a source to clients. The source for CloudFront may be an S3 bucket, any public file server or even your file servers on your private network. The idea behind CF is easy, create a distribution, define the source, define how content of the source may be distributed and let the CF servers around the world cache your content and serve them over a much shorter path to your clients.
Good news is that CF recently added support for uploading resources too, so it means the same way your content are downloaded, they may also be uploaded through CF. You may wonder way would we need that for now, but you will find out the reason when you get the full picture later.
So basically all you have to do is to put S3 as source and CloudFront as serving front together and build up a fast and cheap upload/download service together. But didn't we forget one feature? what will happen to access control?
CF as S3 access control
I'm not going to describe what other benefits CF can bring you, but one important feature of CF is that it allows you to limit user's (or view access) to your content using cryptographically generated URLs or cookies. This meant more or less what we intended to have, except for the fact that using CF you can only set limitations on URLs for:
- IP of accessing client
- time period that a resource may be accessed
Even when those did not match our requirements 100%, they seemed pretty good. The process of generation and verification of URLs also seemed a decent tested one. So we just started.
S3 and CF setup
Setting up S3 and CF is a pretty detailed process that should be best looked up on the AWS documentation again (come on! as a system designer you are not going to let me dictate you what you should do, maybe I have then other intentions, not?) but I will give an overview on the whole structure here:
- an S3 bucket has been created and all the access has been removed from it (look at the bucket policy)
- first CF web distribution has been created with a new access identity. The access identity has been given all the permissions on S3 bucket.
- the default behavior on CF distro has been setup up to provide all the HTTP methods (including PUT and POST) only to verified accessors using signed URL or cookies. This step includes setting up a signer and private/public key pair for signer too.
- this first CF distro and its behavior provides read and write access to URLs generated and signed.
- a second CF distribution has been then created on same S3 bucket, using the same access identity used for the first CF distribution.
- the default behavior of second distro has been setup to only provide GET, OPTIONS and HEADERS methods again only to signed URLs or cookies. You would best use another signer for this distro to increase security.
Following picture shows what stated above:
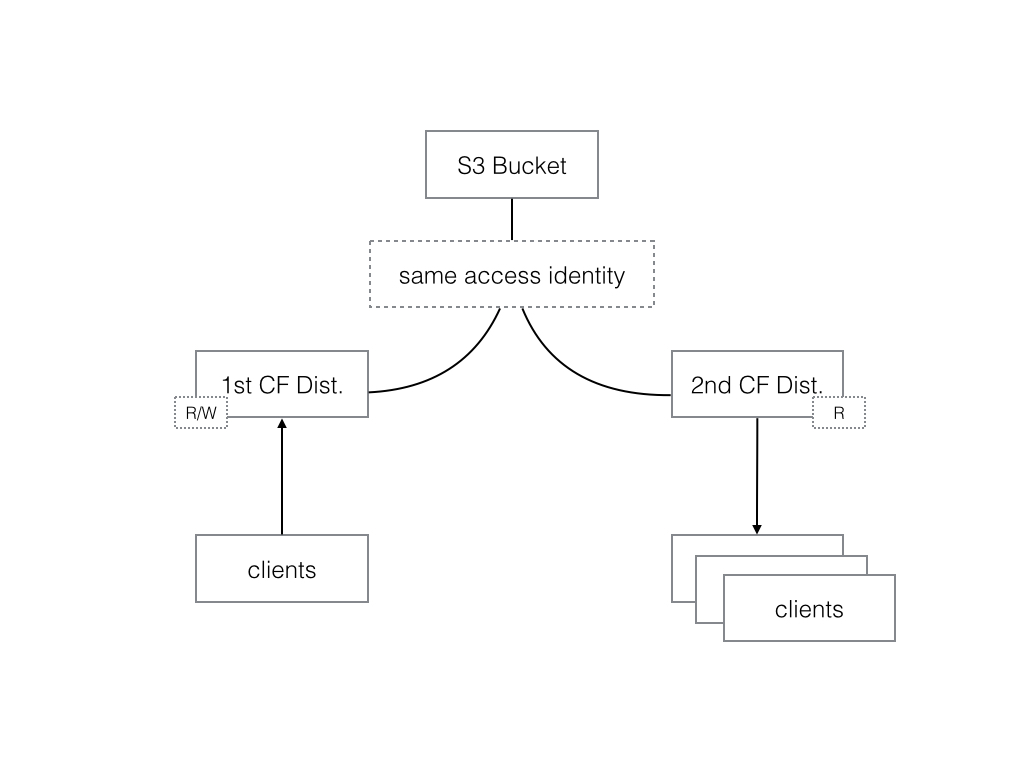
The very important part here is to note that the same identity shall be used for both CF distributions. This is due to the fact that CF sets special permissions so that it is only this identity (which will be the uploader identity) has access to data. It means if you use any other identity in your second CF distro, you will only get 403 errors back. Funny is that even the AWS root account can not access those files (at least at the time of this writing). You can not even change permissions using S3 console to access those files!
URL generation and the rest
The rest of the process depends pretty much on your system's design. You need some process in your system to use your private keys and generate proper URLs. We used AWS SDK for Java and this generation was done in only some lines of code. You may also decide to implement that functionality on your own (which I would not recommend).
We process our access control logic on our own servers and send back proper, read only or read write, URLs back to users if they have proper rights. Clients then use those URLs to either upload, retry upload or to retrieve the files from CF and S3.
You have to also consider some other facts like how you generate URLs and file paths in order to prevent conflicts (multiple uploaders overwrite each others' files). You shall tune the validity time of your URLs based on URL type (read or r/w), client's rights and maybe some other facts.
We experimented with this setup and results where great both in terms of performance and reliability. The best thing is that using this setup there is no bottleneck and single point of failure in system. You may even consider S3 replication in multiple AWS availability zones.